Acoustics Experiment Shows Why It’s So Hard to Make Out the Heroine’s Words at the Opera
DOI: 10.1063/1.1712489
A frustrated listener might well define grand opera as musical theater where you have a hard time making out the words even when they’re being sung in your own language. Conceding the point, many opera houses nowadays always flash surtitles above the proscenium. Comprehension is particularly difficult in the higher reaches of the soprano register. Hector Berlioz long ago warned composers not to put crucial words in the soprano’s mouth at high notes.
A recent study at the University of New South Wales in Sydney, Australia, lays most of the blame on an inescapable tradeoff dictated by the physical acoustics of vowel differentiation and singing very high notes. Acoustical physicists John Smith and Joe Wolfe, working with physics undergraduate Elodie Joliveau, have carried out an experiment that demonstrates why different vowel sounds are almost impossible to distinguish when sopranos are singing in the highest octave of their range. 1
The experimental subjects were eight professional operatic sopranos. Joliveau is herself a soprano, Wolfe is a composer and woodwind player, and Smith plays the double bass. The experimenters used equipment developed by Smith and Wolfe for the analysis of acoustic resonances in musical instruments and in the vocal tract during ordinary speech. The equipment is, in fact, designed to help adults master the sounds, especially the vowels, of a new language. It’s also being applied to the correction of speech pathologies.
Vocal tract resonances
In ordinary speech or singing, the fundamental pitch frequency
To make the various vowel sounds, a speaker or singer must change these vocal-tract resonances by altering the configuration of tongue, jaw, and lips. The distinction between different vowel sounds in Western languages is determined almost entirely by
For the vowel sound in “hood,” as pronounced by a male speaker of “standard” Australian,
For women, the characteristic resonance frequencies for a given vowel sound are roughly 10% higher. But for both sexes, the pitch frequency
Striving to be heard in the last row of a large opera house, often in competition with a full orchestra, a soprano needs all the help her vocal-tract resonances can provide. But
In the 1970s, Johan Sundberg (Royal Institute of Technology, Stockholm), a pioneer in the analysis of singing acoustics, presented evidence that the tricks sopranos are traditionally taught for maintaining volume at high notes (“open your mouth very wide and smile”) actually serve to raise
The Sydney experiment
By contrast, the Sydney group’s new technique probes the vocal tract almost continuously over the frequency range 0.2–4.5 kHz. Adjacent to a microphone touching the subject singer’s lower lip is an acoustical current source—the output horn of an electronic sound synthesizer that is calibrated to present the microphone with a flat broadband frequency spectrum when the singer is silent with her mouth closed.
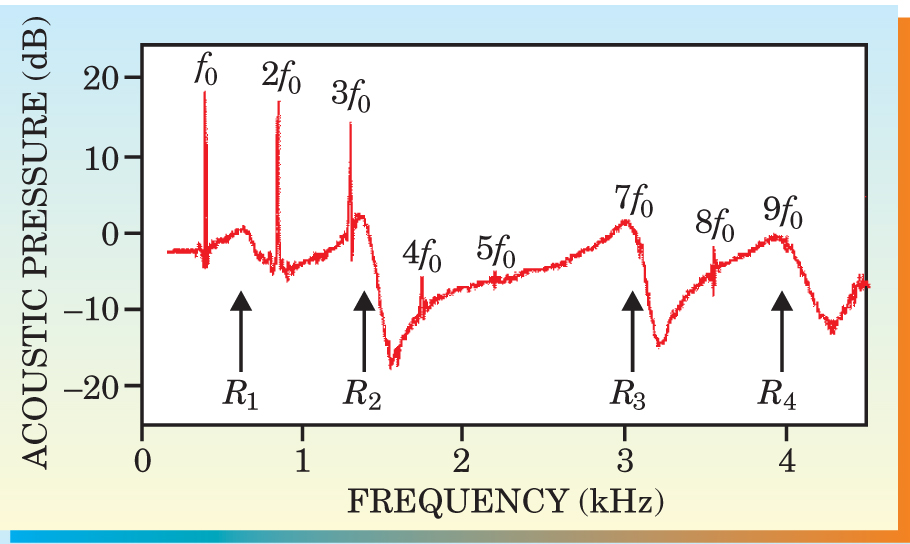
In the Sydney experiment, the subject sang a sustained note with a given vowel sound while the synthesizer was on. Thus the frequency spectrum recorded by the microphone (see figure 1) combined the narrow spikes of the singer’s fundamental pitch frequency and its overtones with the much broader, but still well-defined, peaks that exhibit the modification of the synthesizer output by the resonances in that particular vocal-tract configuration. The spectrum in figure 1 was produced by a soprano sustaining the note A4 (440 Hz) for four seconds with the vowel sound in “hard.” The observed

Figure 1. Simultaneous measurement of the harmonic spectrum of a soprano singing and of the resonant effect of her vocal tract on the flat, broadband frequency spectrum from a synthesizer just outside her mouth. The soprano sustained the note A4 (fundamental frequency
(Adapted from ref. 1.)
But what happens to the first vocal-tract resonance as the soprano goes up the scale to higher notes? Figure 2 plots the Sydney experiment’s measured change of

Figure 2. Measured rise of the first vocal-tract resonant frequency
(Adapted from ref. 1.)
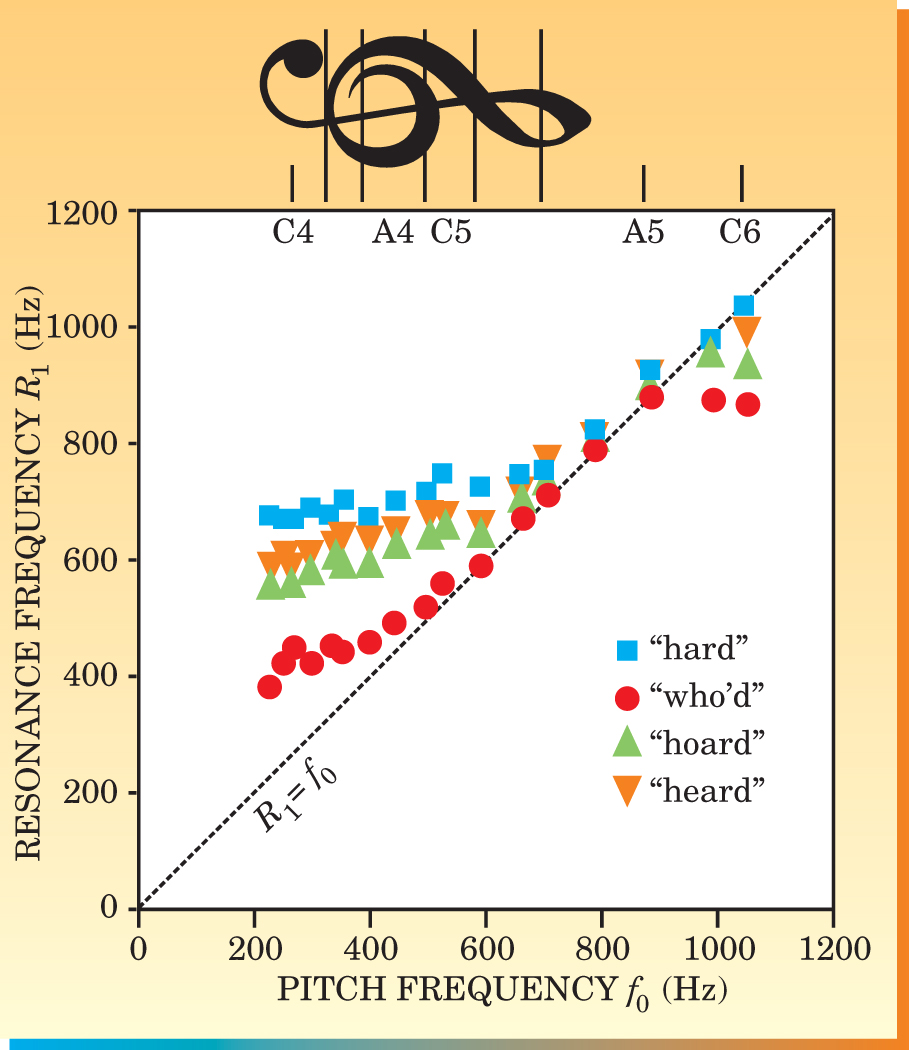
If these plateaus were to continue to higher pitch frequencies,
Morphologically, what’s happening is that the trained singer is progressively flaring the front end of her vocal tract by lowering her jaw and pulling back the corners of her mouth in an exaggerated smile (see figure 3). The first resonance of an unflared cylinder is at the frequency for which the cylinder’s length is

Figure 3. Soprano Kirsten Butchatsky was a subject in the Sydney group’s experiment.
(Photo courtesy of Joe Wolfe.)

Understanding the words
The asymptotic convergence of
As the first vocal-tract resonances converge with increasing
What if a soprano were willing to forgo the benefits of raising
On the Sydney music-acoustics group’s Web site, 3 one can listen to the gradual disappearance of all vowel distinction as a soprano ascends the scale from C4 to C6. The site also poses a “soprano challenge.” Any classically trained soprano who believes she can maintain clear vowel distinctions at the top of the scale is invited to contact the group. “If we find someone who can indeed defy what we think is a fundamental physical limitation,” says Wolfe, “that would be the basis for a very interesting study.”
References
1. E. Joliveau, J. Smith, J. Wolfe, Nature 427, 116 (2004).https://doi.org/10.1038/427116a
2. J. Sundberg, The Science of the Singing Voice, Northern Illinois U. Press, Dekalb, IL (1987).





{kind=link}
{kind=link}
{kind=link}